Blog posts
2023

Packaging CrowdSec for Debian: Bookworm (Debian 12)
13 June 2023
Moving to the next level during the Bookworm release cycle: catching up with new releases of the Security Engine and packaging Remediation Components.
13 June 2023
Moving to the next level during the Bookworm release cycle: catching up with new releases of the Security Engine and packaging Remediation Components.

Packaging CrowdSec for Debian: Bullseye (Debian 11)
12 June 2023
Taking a look back at the collaboration between CrowdSec and DEBAMAX during the Bullseye release cycle.
12 June 2023
Taking a look back at the collaboration between CrowdSec and DEBAMAX during the Bullseye release cycle.


Groundhog Day: reflashing system images made easy
6 February 2023
Flashing system images without ever touching hardware again? Not impossible!
6 February 2023
Flashing system images without ever touching hardware again? Not impossible!
2022
Helping with PiRogue Tool Suite
21 June 2022
When mobile forensic and network analysis meet Raspberry Pi devices.
21 June 2022
When mobile forensic and network analysis meet Raspberry Pi devices.
2020

systemd: RequiredBy versus WantedBy
14 June 2020
How using the wrong keyword in systemd metadata can lead to unexpected results…
14 June 2020
How using the wrong keyword in systemd metadata can lead to unexpected results…
Installing Jitsi behind a reverse proxy
18 March 2020
What if you already have an Apache set up as a reverse proxy on your infrastructure?
18 March 2020
What if you already have an Apache set up as a reverse proxy on your infrastructure?
Fixing faulty synchronization in Nextcloud
29 February 2020
Sometimes a client sync in Nextcloud goes haywire, here’s a little workaround.
29 February 2020
Sometimes a client sync in Nextcloud goes haywire, here’s a little workaround.
2019

Adding Raspberry Pi CM3 support to Debian Buster
9 September 2019
Debian Buster shipped with almost everything needed to support the Raspberry Pi CM3, let's look at the missing pieces.
9 September 2019
Debian Buster shipped with almost everything needed to support the Raspberry Pi CM3, let's look at the missing pieces.

An overview of Secure Boot in Debian
19 April 2019
Debian Installer Buster Alpha 5 came with initial Secure Boot support, let’s dive into it!
19 April 2019
Debian Installer Buster Alpha 5 came with initial Secure Boot support, let’s dive into it!
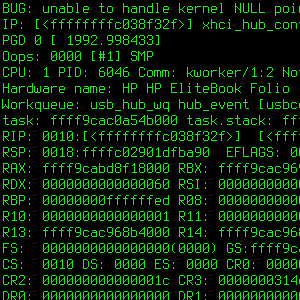
Debugging with netconsole
3 January 2019
The Linux kernel sometimes crashes so badly it leaves little traces around, let’s fix this…
3 January 2019
The Linux kernel sometimes crashes so badly it leaves little traces around, let’s fix this…
2018

Debugging black screen in Debian Installer
25 May 2018
How Linux kernel changes can affect user space in various ways…
25 May 2018
How Linux kernel changes can affect user space in various ways…
2017

Tails: early work on reproducibility
20 November 2017
How DEBAMAX got involved in the early design and implementation phases to bring reproducibility in the Tails world.
20 November 2017
How DEBAMAX got involved in the early design and implementation phases to bring reproducibility in the Tails world.

Debian Installer: Stretch released
4 August 2017
A look back on the last release candidates of the Debian Installer before the final Stretch release.
4 August 2017
A look back on the last release candidates of the Debian Installer before the final Stretch release.
Debian Installer: Stretch RC 2 released
13 February 2017
Discover what happened during the release process of the first release candidates of Stretch’s installer.
13 February 2017
Discover what happened during the release process of the first release candidates of Stretch’s installer.
2016

Debian Installer: Stretch Alpha 8 released
22 November 2016
Check out how the release process went, and discover the biggest change in this release: debootstrap.
22 November 2016
Check out how the release process went, and discover the biggest change in this release: debootstrap.
2015
